
专题课程

近年来,四川总是频繁的发生地震,每次有地震中国地震网都是最快发布消息,作为一名开发人员,对数据是相当过敏的,于是就萌生了爬取网站数据的念头。所以今天通过中国地震网查阅下近年来的地震数据。
关于爬虫,很多人都会想起python,其实爬虫并不局限于python语言,java也可以实现,只是使用的方式不太相同,但原理也是一样的。爬虫大概的流程是,分析数据html结构->使用xpath匹配读取->取得每一行数据->记录到数,首先进入网站首页,我们打开开发者工具来获取到html结构。
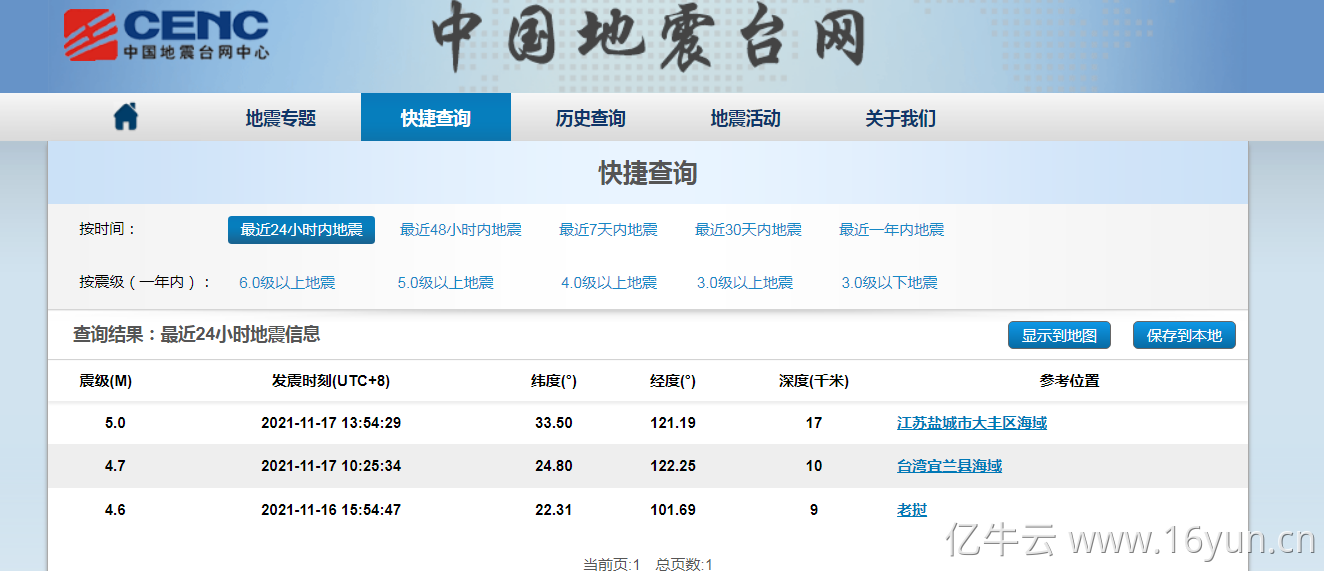
使用java我们可以轻松爬取到网站的数据,并对数据进行分析和保存,因为访问的是历年来的数据,数据量应该不小,所以必须借助代理ip,不然本地是访不了多久的,这里主要是使用的亿牛云爬虫代理动态转发。具体使用示例如下:
import org.apache.commons.httpclient.Credentials;
import org.apache.commons.httpclient.HostConfiguration;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpMethod;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.UsernamePasswordCredentials;
import org.apache.commons.httpclient.auth.AuthScope;
import org.apache.commons.httpclient.methods.GetMethod;
import java.io.IOException;
public class Main {
# 代理服务器(产品官网 www.16yun.cn)
private static final String PROXY_HOST = "t.16yun.cn";
private static final int PROXY_PORT = 31111;
public static void main(String[] args) {
HttpClient client = new HttpClient();
HttpMethod method = new GetMethod("https://httpbin.org/ip");
HostConfiguration config = client.getHostConfiguration();
config.setProxy(PROXY_HOST, PROXY_PORT);
client.getParams().setAuthenticationPreemptive(true);
String username = "16ABCCKJ";
String password = "712323";
Credentials credentials = new UsernamePasswordCredentials(username, password);
AuthScope authScope = new AuthScope(PROXY_HOST, PROXY_PORT);
client.getState().setProxyCredentials(authScope, credentials);
try {
client.executeMethod(method);
if (method.getStatusCode() == HttpStatus.SC_OK) {
String response = method.getResponseBodyAsString();
System.out.println("Response = " + response);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
method.releaseConnection();
}
}
}后续工作,我们经将获取到的数据解析到模型中,然后进行数据分析就可以有精准的数据了,
到这里我们的爬虫流程就结束了,我们可以看到,使用java也是很好使用的,大家觉得呢?




 收藏(0)
收藏(0) 赞
赞 




















